하둡 체험하기는 VMware Workstation Pro / Centos 7 환경에서 진행합니다.
https://growingsaja.tistory.com/84
정상적인 하둡 이용을 위해서는 ssh-key를 통한 원격 접속이 가능하도록 세팅되어야합니다.
https://growingsaja.tistory.com/82?category=790816
하둡 설치는 해당 링크의 tar.gz 파일을 받아 하둡 전용 유저의 홈디렉토리 아래에서 압축을 풀고 /etc/profile 세팅해주면 됩니다.
vim /etc/profile
=============================================
export JAVA_HOME=/usr/local/sbin/jdk
export HADOOP_HOME=/home/hdfsnnuser/hadoop
export HADOOP_PREFIX=/home/hdfsnnuser/hadoop
export PATH=$PATH:$JAVA_HOME/bin:
=============================================
JAVA_HOME은 세팅하신 부분에 따라서 경로 변경해주시면 되겠습니다.
팁 : HADOOP_HOME과 HADOOP_PREFIX 모두 필요로 하지 않으나 버전에 따라 HADOOP_HOME / HADOOP_PREFIX를 요구하니 둘 다 작성해두시면 어떤 버전을 사용하셔도 문제가 발생하지 않아, 혹시 몰라 둘 다 넣었다, 정도로 보시면 되겠습니다.
적용을 위해 source /etc/profile 명령어 진행합니다.
( 추가 팁 하나 더 : /etc/profile 이나 /etc/bashrc 혹은 ~/.bashrc 등의 파일은 서버가 부팅될 때 읽으면서 올라오는 파일들입니다. )
위 링크들에서 필요 작업 진행 후에 진행해주세요.
VM을 통해 작업하므로 네임노드, 데이터노드를 한 대에 설치하겠습니다.
물리적인 서버는 1대지만 논리적으로 여러대
1. JAVA의 경로를 하둡이 알 수 있도록 설정
hadoop-env.sh 에 export javahome 값 풀경로 넣어주기
============================
EX >>
export JAVA_HOME=/usr/local/sbin/jdk
============================
/etc/profile 에 해당 값 넣어주고 source /etc/profile 하는 경우 위 과정을 미진행해도 무방함
/etc/profile
============================
export JAVA_HOME=/usr/local/sbin/jdk
============================
2. core-site.xml (네임노드는 누구인지 설정)

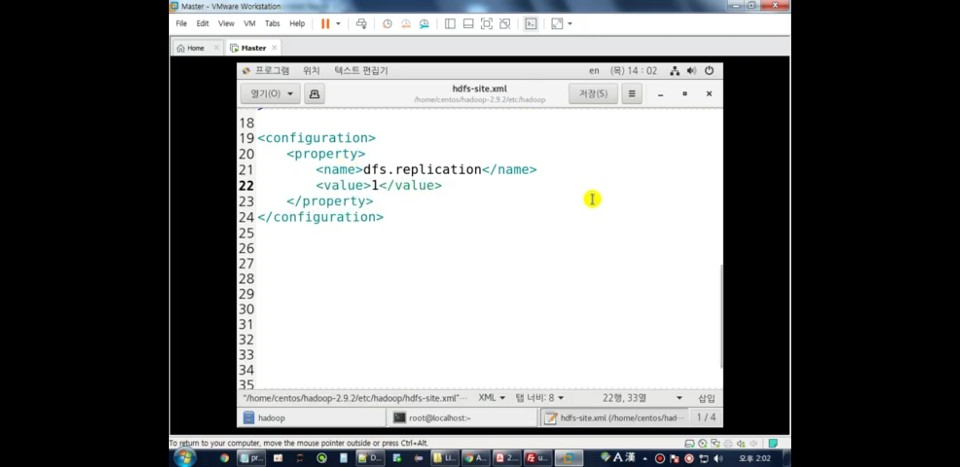
3. hdfs-site.xml (파일을 몇 개로 복제할건지 설정)
4. 네임노드 포맷 작업
# hdfs namenode -format
5. start
# start-dfs.sh
기다리기 시간걸릴수있음
# jps 를 통해 확인
6. start한 NN 웹페이지 확인
http://999.888.777.666:50070
웹 들어가면
네임노드 관련 정보가 나옴
7. node manager, resource manager 시작
# start-yam.sh
# jps
8. 추가적인 정보 웹에서 확인하기
웹페이지
999.888.777.666:8088
하둡 클러스터에 대한 정보 나옴
메모리 얼마나 쓰고있는지
데이터노드 몇개인지 등 볼 수 있음
9. 맵리듀스 job을 실행하기 위한 작업
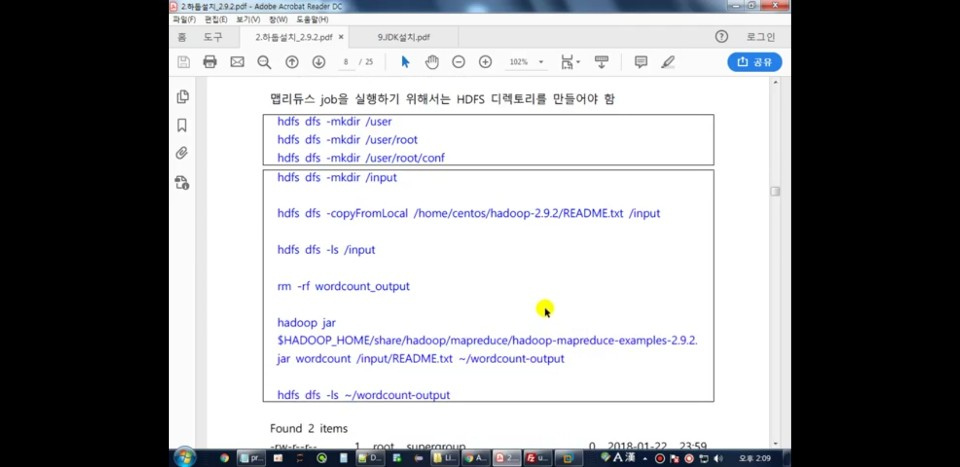
mkdir 할때 명령어 적용시간이 걸리는 이유는 Local PC에 만드는게 아니라 하둡분산파일시스템에 만드는 것이기 때문입니다.
'About Data > Hadoop' 카테고리의 다른 글
| [Hadoop] 하둡 소개 및 기본 구성요소 설명 (0) | 2019.06.03 |
|---|